Restaurant Image Classification using Deep Learning
Crystal Lim, Leonhard Spiegelberg, Virgile Audi and Reinier Maat
AC297r Capstone project
Harvard University
Spring 2016
Abstract
On this website you will find the story of four graduate students who embarked on a real Data Science Adventure: working with and cleaning large amounts of data, learning from scratch and implementing state of the art techniques, resorting to innovative thinking to solve challenges, building our own super-computer and most importantly delivering a working prototype. It had it all. In this project, we tackled the challenge of classying user-uploaded restaurant images on TripAdvisor into five diferent categories: food, drink, inside, outside and menus. To achieve this task, we developed a convolutional neural network model that yielded an average accuracy of 87% over the five caterogies.
Table of Contents
Introduction
How many times have you decided to try a restaurant by browsing pictures of the food or the interior? Images along with reviews are the most important sources of information for TripAdvisor’s users. In order to improve their website experience, TripAdivsor commissioned us to build a classifier for restaurant images. To do so, we implemented a convolutional neural network, a machine learning algorithm inspired by biological neural networks, to classify pictures into 5 classes:
| Food | Drinks | Interior | Exterior | Menu |
|---|---|---|---|---|
 |
 |
 |
 |
 |
The Journey
The Data Collection Process
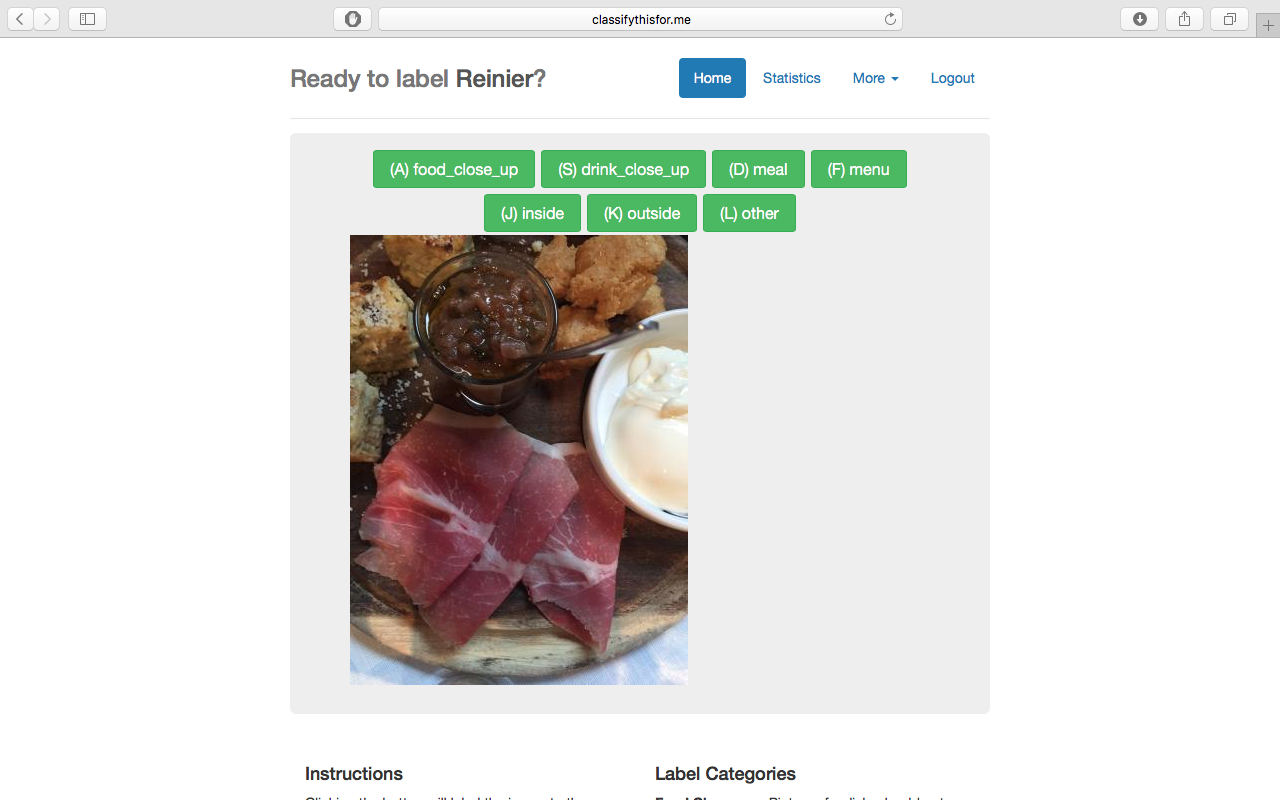
Labeling
In order to build an accurate classifier, the first vital step was to construct a reliable training set of photos for the algorithm to learn from, a set of images that are pre-assigned with class labels (food, drink, menu, inside, outside). We received 200,000 unlabeled TripAdvisor images to use. To assign these images correct labels, we developed a web-based image labeling service with a PHP/MySQL server backend. Using a contest system we were able to effectively create a platform for multiple users to assign images to their appropriate classes. This design was advantageous in that it provided a simple method for producing a training set in a cost-effective and immediate manner. It also allowed us to quickly scan through the data with on-the-fly labelling which gave us valuable insight into the kind of images we were actually dealing with.
Augmentation
We augmented our data with labeled images from publicly available sources, like ImageNet. The sources used were generally of high quality, providing us with a large batch of clean images with correct labels. This helped us boost our training performance by supplying more reliable samples to the algorithm.
Building The Model
Background
Neural Networks
Neural Networks are machine learning models fashioned after biological neural networks of the central nervous system. Like their biological counterparts, artificial neural networks allow information to be passed using collections of neurons. Each neuron in a layer within the neural network is a processing unit which takes in multiple inputs and produces an output. For each neuron, every input has an associated weight which modifies the strength of each input. The neuron simply adds together all the inputs and calculates an output to be passed on.
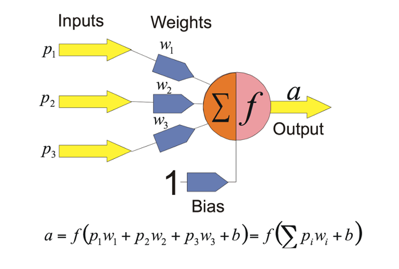
The key advantage of using a neural network is that it learns on its own without explicitly telling it how to solve the given problem. Given input and output data, or examples from which to train on, we construct the rules to the problem. This allows us to bypass manually extracting features from the input. During the process of training the model, neurons reaching a certain threshold within a layer fire to trigger the next neuron. In this way, not all neurons are activated, and the system learns which patterns of inputs correlate with which activations. Additional adjustments are made using backpropagation, a feedback process which allows differences between actual outputs and intended outputs to modify the weights within the network.
Convolutional Neural Networks
Our classifier employs a Convolutional Neural Network (CNN), which is a special type of neural network that slides a kernel over the inputs yielding the result of the convolution as output. CNNs combine the two steps of traditional image classification, i.e. a feature extraction step and a classification step. The network will learn on its own and fit the best filters (convolutions) to the data. However, for it to work successfully, it requires tens of thousands of labeled training images.
We use CNNs, because in contrast to many other applications that use neural networks, using fully connected layers is not feasible for images since the feature space is too large (a small 256x256 image with 3 channels already has a feature vector size of 196,608). However, images have locally correlated features. Hence, we can ignore distant pixels and consider only neighboring pixels, which can be handled as a 2D convolution operation.

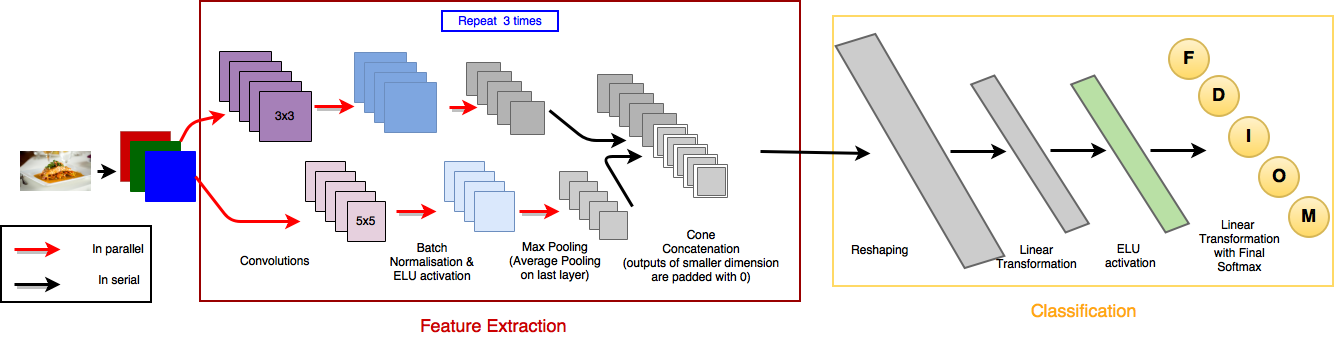
Architecture
A CNN consists of multiple layers of convolutional kernels intertwined with pooling and normalization layers, which combine values and normalize them respectively. Its final step uses a fully connected multi-layer perceptron to give us the actual predicted classes for each input image.
More specifically, the CNN consists of sequential substructures all containing a number of 3x3 kernels, batch normalization, an exponential linear unit (ELU) activation fuction and a pooling layer that gets the maximum value from each convolution. This is followed by the fully connected layer, outputting the predicted class.
The architecture was optimized to its current state by iteratively introducing best practices from prior research.
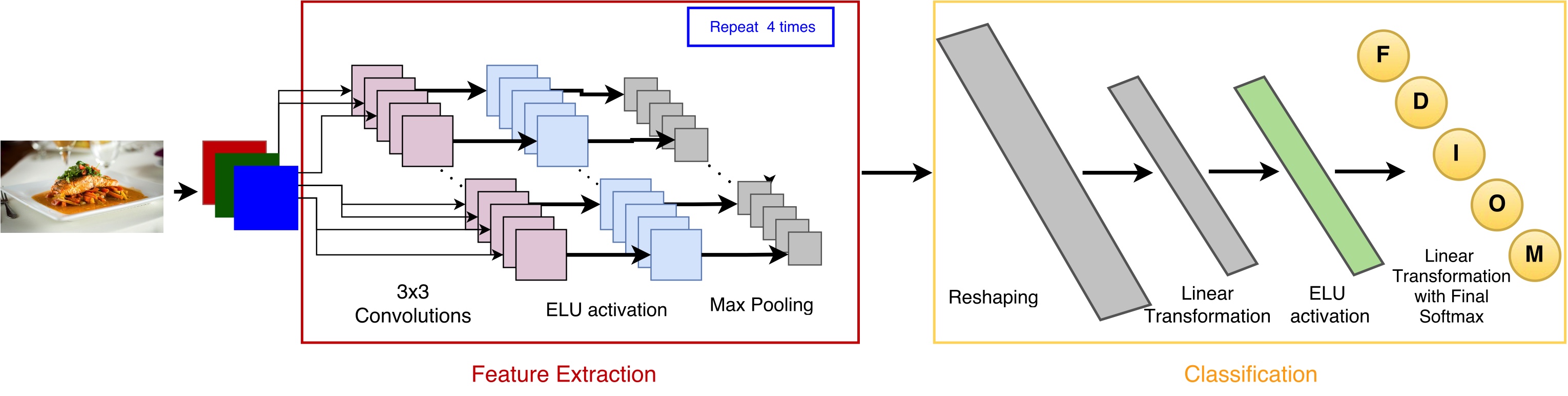
The architecture presented above led to relatively good results, which can be found below. We nevertheless tried to improve the results by introducing kernels of different sizes. Therefore, instead of having 4 layers of only 3x3 kernels, we combined 5x5 and 3x3 kernels in 3 layers which resulted in an alternative architecture.
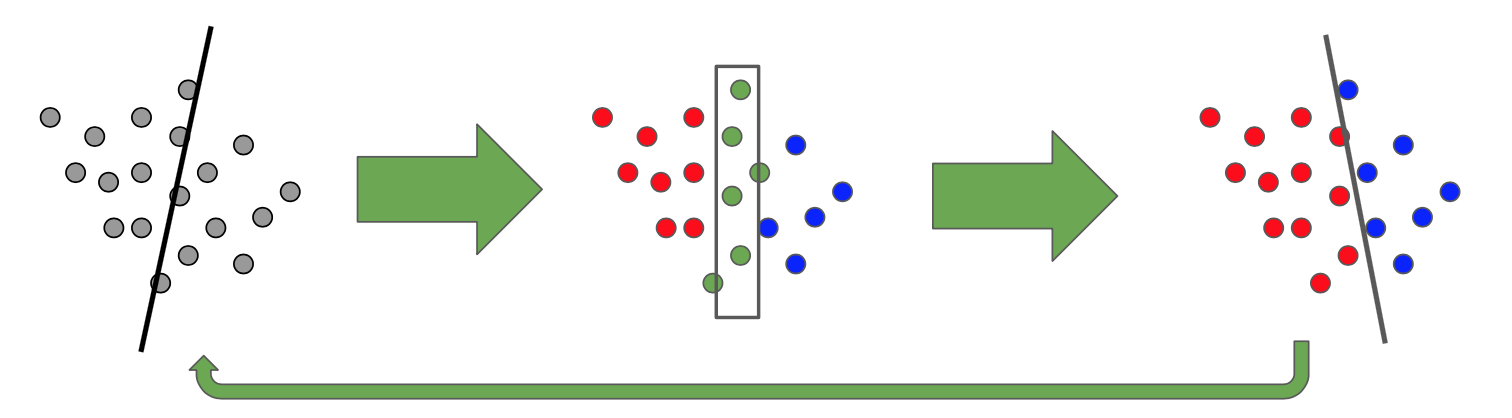
Active Learning
Performance was significantly impacted by the quality of training data. Therefore, to improve results, we began implementing an iterative method to build an optimal training set, known as active learning. Active learning is a way to effectively reduce the number of images needed to be labelled in order to reach a certain performance by supplying information that is especially relevant for the classifier. In our case, this is comprised of images the algorithm was confused about (it does not know which of two or more categories to put it in). By labeling this set of pictures, the algorithm should get a lot of information on the decision boundary between classes. Stepwise it is defined like this:
- Train a classifier and predict on unseen data
- Evaluate points that are close to the boundary decision (confused points)
- Manually label these points and add them to the training set
Visually, it can be represented by the following pipeline:
Tools
Software
We used the Torch7 scientific computing toolbox together with its just-in-time compiler LuaJIT for LUA to run all of our computations. Torch provides ease of use through the Lua scripting language while simulateously exposing the user to high performance code and the ability to deploy models on CUDA capable hardware. This made it well-suited for the needs of our project.
Hardware
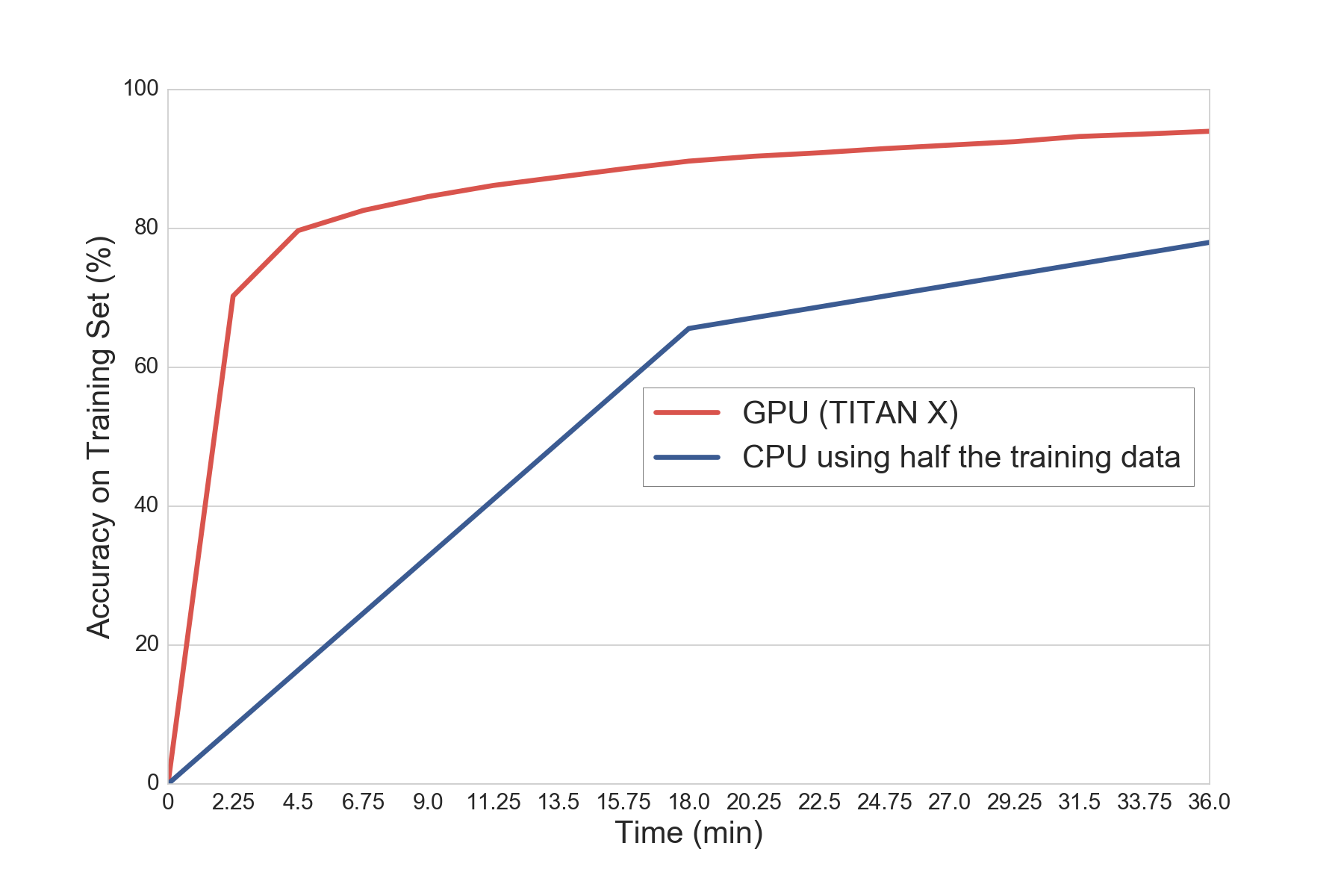
Working with convolutional neural networks is computationally very expensive. Early on in the model building processes, we hit a computational wall working on our laptops (though they actually were fast). Thanks to the support of TripAdvisor, we were able to solve this issue by building our own working station which ran using a GeForce Titan X card. Though this at first sounded like an easy task, setting it up and making it work required several weeks. But the reward of having it was worth every hour we spent. Running the code on a GPU allowed us to try more complex models due to lower runtimes and yielded significant speedups – up to 20x in some cases.
Results
### Quantitative results After training the CNN, we predicted the correct labels on a set of held-out test data. The first architecture presented above yielded an accuracy of 85.60%. We present more detailed results in the form of a confusion matrix here:
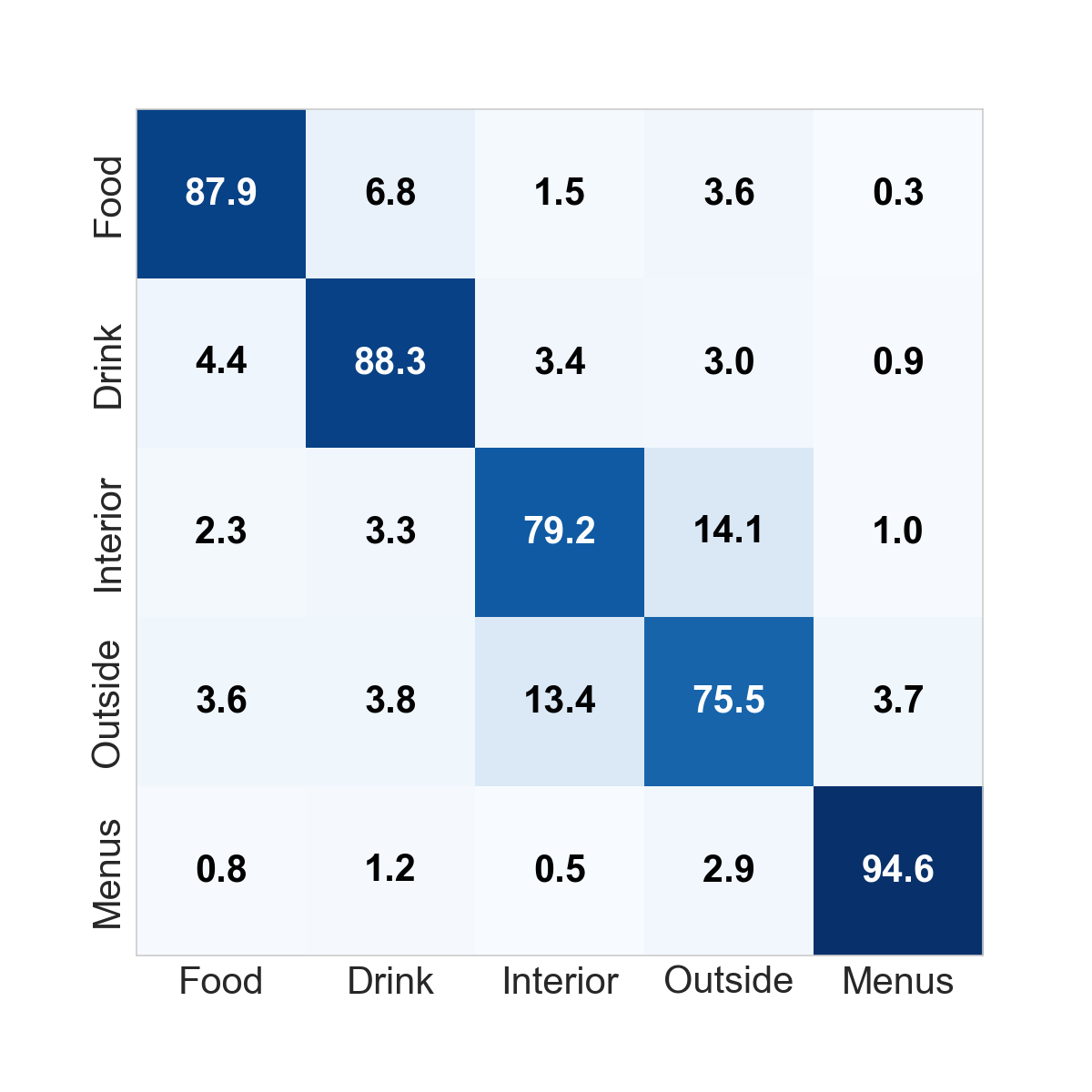
As one can see, this first architecture worked extremely well on Menus and had very good performance on Food and Drink. The main issue with this architecture was the relatively significant confusion between Inside and Outside. To correct this, we introduced architecture 2 above which yielded the following results:
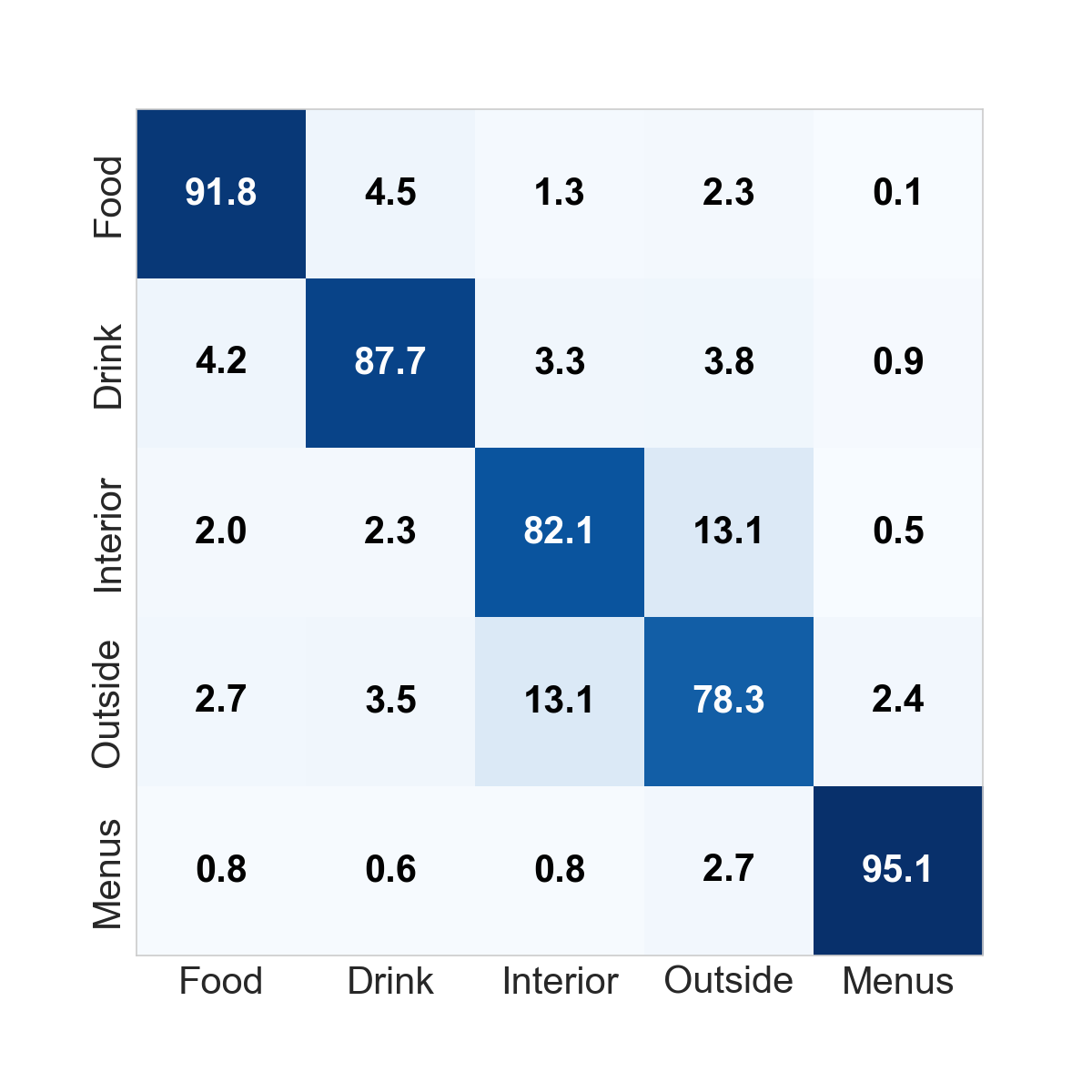
This architecture improved the results, obtaining a new average accuracy of 87.02%. Overall, performance improved on all categories except the Drink category and helped reduce the confusion between Inside and Outside labels.
Qualitative Results
In the following we are demonstrating some of the pictures the algorithm is capable of of correctly detecting right now:

However, our algorithm is not yet perfect and pictures are sometimes misclassified. Sometimes the algorithm is confused about pictures that may belong to two possible classes. For instance, the picture below was classified as an Inside picture, but it seems to be more of a terrace. Will the end user be upset to find this picture in the Inside category?

Even more difficult, is this photo a picture of the beach or a drink? The algorithm classified it as an Outside picture but it would have been completely correct if it had chosen drink!

Of course, it would have been fantastic if we only had issues with pictures for which even humans have trouble choosing the correct categories. Unfortunately, that is still not the case and sometimes the algorithm is plain wrong. We narrowed some of the issues that could cause a misclassification including lighting, particular features of a class that appear sporadically in a picture of a different class or image quality itself.

Discussion
Challenges
Since this project was open-ended, the main challenge was to make the best design decisions. For example, we decided what and how much data to request, what the architecture of our model was going to be, and which tools to use to run the model.
Designing a good training set was especially challenging, because the labels we wanted to output were not neccesarily mutually exclusive. For examle, any image of food or drinks can be taken inside or outside. The algorithm returning that label is technically not wrong, but it is less relevant to the user. Also, the labels must be represented uniformly in order for the algorithm to learn best. Labeling with many people does not help. We circumvented this problem partly with data augmentation and a strict specification of the labels.
Future Work
As part of the future work, we would add more active learning rounds to improve the algorithm’s performance along its decision boundary, which consists of pictures about which the algorithm is most confused.
It may also be worth exploring multiple labels per picture, because in some cases multiple labels logically apply, e.g. an inside picture of food. In this case multiple CNNs can train for the presence of one particular label in parallel. This could improve performance and give the end-user more relevant information about the picture.
Conclusion
We developed a convolutional neural network model that classifies restaurant images, yielding an average accuracy of 87% over the five caterogies. We built the pipeline from front to end: from the initial data request to building a labeling tool, and from building a convolutional neural network (CNN) to building a GPU workstation.
By employing active learning in the CNN we reduced the amount of labels needed to train the model in order to improve performance. Running the model on a GPU rather than a CPU reduced the learning time dramatically, thereby allowing for more complex network architectures to improve predictive performance. Since there was no (cost-)effective labeling pipeline available, we also developed a web interface that allows us to label images easily and to host labeling competitions for larger-scale labeling efforts.
We would like to thank TripAdvisor and the AC297r staff for helping us complete this important Data Science project. And now that you know a bit more about our journey, you can see how well the model actually performs! We have uploaded the model on a server fetching random images from TripAdvisor. Head to here to see it in action and thanks for reading this entry!